Status Writer::AddRecord(const Slice& slice){ constchar* ptr = slice.data(); size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice // is empty, we still want to iterate once to emit a single // zero-length record Status s; bool begin = true; do { constint leftover = kBlockSize - block_offset_; assert(leftover >= 0); if (leftover < kHeaderSize) { // 不够七个字节 // Switch to a new block if (leftover > 0) { // Fill the trailer (literal below relies on kHeaderSize being 7) static_assert(kHeaderSize == 7, ""); dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover)); } block_offset_ = 0; }
// Invariant: we never leave < kHeaderSize bytes in a block. assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
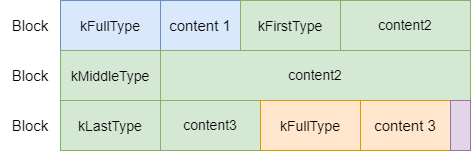
RecordType type; constbool end = (left == fragment_length); if (begin && end) { type = kFullType;// 当前Log Block里的空间足以容纳写入的数据 } elseif (begin) { type = kFirstType;// 当剩余空间不够,且刚开始装数据,则当前record为第一个 } elseif (end) { type = kLastType;// 当剩余空间够,且不是第一次装数据了,则当前record为末尾 } else { type = kMiddleType; }
s = EmitPhysicalRecord(type, ptr, fragment_length);// 写入文件 ptr += fragment_length; left -= fragment_length; begin = false; } while (s.ok() && left > 0); return s; }
// REQUIRES: mutex_ is held // REQUIRES: this thread is currently at the front of the writer queue Status DBImpl::MakeRoomForWrite(bool force){ mutex_.AssertHeld(); assert(!writers_.empty()); bool allow_delay = !force; Status s; while (true) { // 后台出现错误 if (!bg_error_.ok()) { s = bg_error_; break; // 如果level0有太多文件,则睡眠一会儿等待合并再执行一会儿 } elseif (allow_delay && versions_->NumLevelFiles(0) >= config::kL0_SlowdownWritesTrigger) { mutex_.Unlock(); env_->SleepForMicroseconds(1000); allow_delay = false; // Do not delay a single write more than once mutex_.Lock(); // 有足够空间 } elseif (!force && (mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) { // There is room in current memtable break; // imm还没彻底落盘,需要等待 } elseif (imm_ != nullptr) { Log(options_.info_log, "Current memtable full; waiting...\n"); background_work_finished_signal_.Wait(); // level0还是有太多文件,则等待合并完成 } elseif (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) { Log(options_.info_log, "Too many L0 files; waiting...\n"); background_work_finished_signal_.Wait(); } else { // Memtable满了,则创建新的log文件和新的Memtable,并将原Memtable标记为imm,并创建一个后台线程开始尝试compaction assert(versions_->PrevLogNumber() == 0); uint64_t new_log_number = versions_->NewFileNumber(); WritableFile* lfile = nullptr; s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile); if (!s.ok()) { versions_->ReuseFileNumber(new_log_number); break; } delete log_; delete logfile_; logfile_ = lfile; logfile_number_ = new_log_number; log_ = new log::Writer(lfile); imm_ = mem_; has_imm_.store(true, std::memory_order_release); mem_ = newMemTable(internal_comparator_); mem_->Ref(); force = false; // Do not force another compaction if have room MaybeScheduleCompaction(); } } return s; }
Level N –> Level N +1 1)选择一个 Level N的文件,考虑上一次compaction做到了哪个key,然后大于该key的第一个文件即为level N的所选文件。 2)查找所有和该文件由重复key的Level N +1的文件。 3)compaction,生成新的Level N + 1的文件。
Copyright Notice: All articles in this blog are licensed under BY-NC-SA unless stating additionally. Please give credit to the original author when you use it elsewhere.