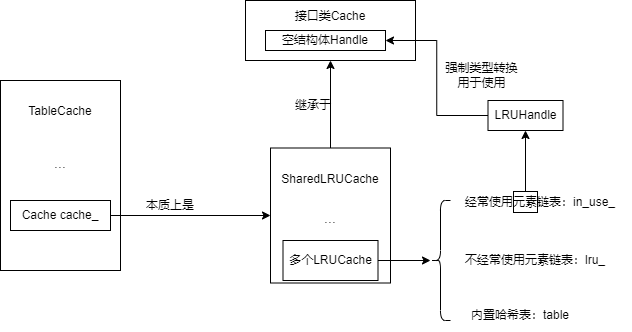
Status TableCache::FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle** handle){ Status s; char buf[sizeof(file_number)]; EncodeFixed64(buf, file_number); Slice key(buf, sizeof(buf)); *handle = cache_->Lookup(key);// 先看看想要的文件是否已经加载到缓存中 if (*handle == nullptr) { // ldb和sst都是SSTable文件的有效后缀? 那为什么要分两种---只是新版本的源码扩展名为“.ldb”,同时向下兼容,支持老版本的扩展名“.sst” std::string fname = TableFileName(dbname_, file_number); RandomAccessFile* file = nullptr; Table* table = nullptr; s = env_->NewRandomAccessFile(fname, &file); // 打开文件 if (!s.ok()) { std::string old_fname = SSTTableFileName(dbname_, file_number); if (env_->NewRandomAccessFile(old_fname, &file).ok()) { s = Status::OK(); } } // 根据file打开文件并解析,加载到table中 if (s.ok()) { s = Table::Open(options_, file, file_size, &table); }
if (!s.ok()) { assert(table == nullptr); delete file; // We do not cache error results so that if the error is transient, // or somebody repairs the file, we recover automatically. } else { TableAndFile* tf = new TableAndFile; tf->file = file; tf->table = table; // key是文件号的编码值 *handle = cache_->Insert(key, tf, 1, &DeleteEntry); } } return s; }
structLRUHandle { void* value; // 由LRUCache中Insert函数构造LRUHandle的过程可知,这个value的类型仍然是TableAndFile* ,内部包含了env的文件和一个table void (*deleter)(const Slice&, void* value); LRUHandle* next_hash; LRUHandle* next; LRUHandle* prev; size_t charge; // 占用cache空间数目,目前始终为1 size_t key_length; bool in_cache; // 表示当前元素是否在cache中,false表示回收内存 uint32_t refs; // 当引用计数为0时就要删除 uint32_t hash; // Hash of key(); used for fast sharding and comparisons char key_data[1]; // key值,同样是末尾,意味着可变长
Slice key()const{ // next is only equal to this if the LRU handle is the list head of an // empty list. List heads never have meaningful keys. assert(next != this);
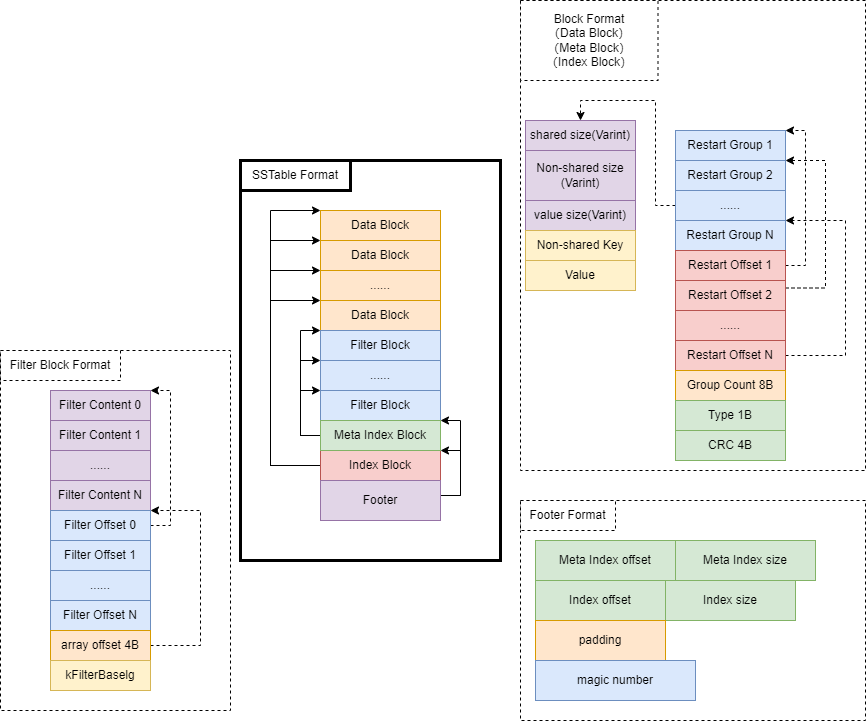
Status Table::Open(const Options& options, RandomAccessFile* file, uint64_t size, Table** table){ *table = nullptr; if (size < Footer::kEncodedLength) { return Status::Corruption("file is too short to be an sstable"); }
char footer_space[Footer::kEncodedLength]; Slice footer_input; // 读Footer Status s = file->Read(size - Footer::kEncodedLength, Footer::kEncodedLength, &footer_input, footer_space); if (!s.ok()) return s;
Footer footer; s = footer.DecodeFrom(&footer_input); if (!s.ok()) return s;
// 读index block BlockContents index_block_contents; ReadOptions opt; if (options.paranoid_checks) { opt.verify_checksums = true; } s = ReadBlock(file, opt, footer.index_handle(), &index_block_contents);
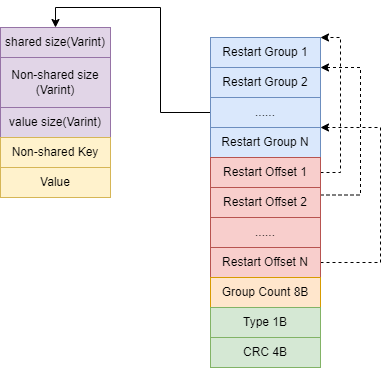
voidSeek(const Slice& target)override{ // Binary search in restart array to find the last restart point // with a key < target // left right指的是在第几个Group uint32_t left = 0; uint32_t right = num_restarts_ - 1; int current_key_compare = 0;
// 优化1 // 首先通过当前的record判断目标key所在的record是在当前record的前面(record > target)还是后面(record < target) if (Valid()) { // If we're already scanning, use the current position as a starting // point. This is beneficial if the key we're seeking to is ahead of the // current position. current_key_compare = Compare(key_, target); if (current_key_compare < 0) { // key_ is smaller than target left = restart_index_; } elseif (current_key_compare > 0) { right = restart_index_; } else { // We're seeking to the key we're already at. return; } }
while (left < right) { uint32_t mid = (left + right + 1) / 2; uint32_t region_offset = GetRestartPoint(mid);// 找到mid所属Group的起点 uint32_t shared, non_shared, value_length; constchar* key_ptr = DecodeEntry(data_ + region_offset, data_ + restarts_, &shared, &non_shared, &value_length); if (key_ptr == nullptr || (shared != 0)) { CorruptionError(); return; } Slice mid_key(key_ptr, non_shared);// 求出所属Group起点的key的公共部分 if (Compare(mid_key, target) < 0) { // Key at "mid" is smaller than "target". Therefore all // blocks before "mid" are uninteresting. left = mid; } else { // Key at "mid" is >= "target". Therefore all blocks at or // after "mid" are uninteresting. right = mid - 1; } }
// We might be able to use our current position within the restart block. // This is true if we determined the key we desire is in the current block // and is after than the current key. // 优化2 // 假如二分查找到的还原点是此时迭代器所在的那个restart_index_,并且迭代器当前指向的key< target,那么可以从此时迭代器的位置开始向后遍历查找数据, // 这样快一些,而不是从这个recordGroup的第一个entry开始遍历。 assert(current_key_compare == 0 || Valid()); bool skip_seek = left == restart_index_ && current_key_compare < 0; if (!skip_seek) { SeekToRestartPoint(left); } // Linear search (within restart block) for first key >= target // 最后进行线性搜索,直到知道第一个大于等于target的key,其中ParseNextKey起到向后移动一格并且将key_更新为当前key值得作用 while (true) { if (!ParseNextKey()) { return; } if (Compare(key_, target) >= 0) { return; } } }
Copyright Notice: All articles in this blog are licensed under BY-NC-SA unless stating additionally. Please give credit to the original author when you use it elsewhere.