// 不是特判,是当前w在别的writebatch整合里面已经被写了 if (w.done) { return w.status; }
// May temporarily unlock and wait. // 整个过程会导致数据库内部的一系列变化,例如:immutable memtable的落盘,后台的compaction等等。最后的结果是active的memtable中应当有足够的位置来容纳接下来的batch write。 Status status = MakeRoomForWrite(updates == nullptr); uint64_t last_sequence = versions_->LastSequence(); Writer* last_writer = &w; if (status.ok() && updates != nullptr) { // nullptr batch is for compactions // 这个函数的目的主要是对队列后的一些请求作整合,有做大小限制,并对sync的请求有单独处理。 WriteBatch* write_batch = BuildBatchGroup(&last_writer); // last_writer会变 WriteBatchInternal::SetSequence(write_batch, last_sequence + 1); // 一个writebatch里可能有多个record last_sequence += WriteBatchInternal::Count(write_batch);
// Add to log and apply to memtable. We can release the lock // during this phase since &w is currently responsible for logging // and protects against concurrent loggers and concurrent writes // into mem_. { mutex_.Unlock(); // 写入log status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); bool sync_error = false; if (status.ok() && options.sync) { // 立即把log刷盘 status = logfile_->Sync(); if (!status.ok()) { sync_error = true; } } // 写入memtable if (status.ok()) { status = WriteBatchInternal::InsertInto(write_batch, mem_); } mutex_.Lock(); if (sync_error) { // The state of the log file is indeterminate: the log record we // just added may or may not show up when the DB is re-opened. // So we force the DB into a mode where all future writes fail. RecordBackgroundError(status); } } if (write_batch == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence); }
while (true) { Writer* ready = writers_.front(); writers_.pop_front(); if (ready != &w) { ready->status = status; ready->done = true; ready->cv.Signal(); } if (ready == last_writer) break; }
// Notify new head of write queue if (!writers_.empty()) { writers_.front()->cv.Signal(); }
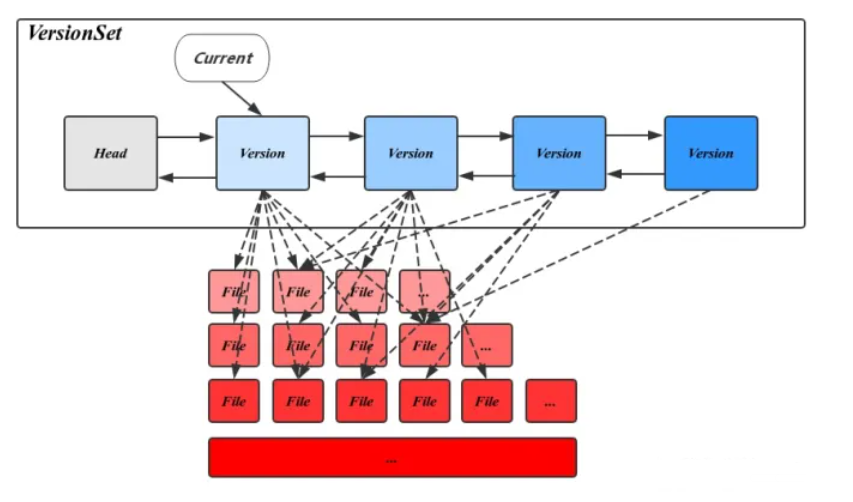
classVersion{ ··· VersionSet* vset_; // VersionSet to which this Version belongs Version* next_; // Next version in linked list Version* prev_; // Previous version in linked list int refs_; // Number of live refs to this version
// List of files per level std::vector<FileMetaData*> files_[config::kNumLevels];// 二维数组,所有level文件的元数据
// Next file to compact based on seek stats. FileMetaData* file_to_compact_; // 当文件查找到一定次数时,就需要执行合并操作 int file_to_compact_level_;
// Level that should be compacted next and its compaction score. // Score < 1 means compaction is not strictly needed. These fields // are initialized by Finalize(). double compaction_score_; // 当score>=1时,也需要进行合并 int compaction_level_; };
// Search level-0 in order from newest to oldest. // 因为第0层可能有重复元素,所以需要对每个文件做出判断。 std::vector<FileMetaData*> tmp; tmp.reserve(files_[0].size()); for (uint32_t i = 0; i < files_[0].size(); i++) { FileMetaData* f = files_[0][i]; if (ucmp->Compare(user_key, f->smallest.user_key()) >= 0 && ucmp->Compare(user_key, f->largest.user_key()) <= 0) { tmp.push_back(f); } } if (!tmp.empty()) { std::sort(tmp.begin(), tmp.end(), NewestFirst); for (uint32_t i = 0; i < tmp.size(); i++) { // 调用Match函数 if (!(*func)(arg, 0, tmp[i])) { return; } } }
// Search other levels. for (int level = 1; level < config::kNumLevels; level++) { size_t num_files = files_[level].size(); if (num_files == 0) continue;
// Binary search to find earliest index whose largest key >= internal_key. // 对其他level只用找一个可能的文件,这里的FindFile内部使用的是二分查找,找到相关文件 uint32_t index = FindFile(vset_->icmp_, files_[level], internal_key); if (index < num_files) { FileMetaData* f = files_[level][index]; if (ucmp->Compare(user_key, f->smallest.user_key()) < 0) { // All of "f" is past any data for user_key } else { if (!(*func)(arg, level, f)) { return; } } } } }
Copyright Notice: All articles in this blog are licensed under BY-NC-SA unless stating additionally. Please give credit to the original author when you use it elsewhere.