leveldb基本组件源码阅读
Slice
Slice是leveldb中的字符串类型,对C风格的字符串和C++的String做了简单封装。为什么要封装呢?
- 相比于拷贝string,拷贝slice代价很小,只用拷贝头指针和长度
- 修改的代价也小,同样是只用修改头指针和长度
- 标准库不支持remove_prefix和starts_with等函数,不太方便
这里要注意的是,头指针指向的字符串并不是在Slice中的构造函数malloc或者new的分配的,可能提前分配好,也有可能创建Slice后交给某个函数分配。因此在使用过程中,要尤其注意某个Slice中的底层数据是否存在。
1 | class LEVELDB_EXPORT Slice { |
Arena内存管理
首先Arena是一个内存管理工具,用于MemTable。那么这里,就不禁问一个问题:为什么不直接用malloc/free或者new/delete。
- 数据库插入单个键值时,在大多数的情况下,一个键值所需要的内存较小,而malloc/free或者new/delete的调用开销较大,如果有大量的小空间分配请求,频繁的调用和分配就很慢。因此一个合理的思想就是:对于小块内存的分配,我一次性分配多一点,之后的分配如果剩余空间够用,就直接从里面取。
这种做法会导致内存碎片(如果第二次分配大于剩余空间,就会重新分配一个块),牺牲了内存利用率,提高了速度。但是在这种应用场景是合理的,数据库插入一个键值在大多数的情况下,所需要的内存较小。
要补充说明的是,Arena只在MemTable(SkipList)中使用,因为其他地方都是大块的分配,就不需要这种优化方式。
1 | inline char* Arena::Allocate(size_t bytes) { |
SkipList
Data Structure
SkipList本质是一个多层有序链表,在普通链表的基础上增加了多级索引,实现节点的快速跳跃,结构简单,且查询速度较快。
查找某个元素时,从图中的左上角开始,逐渐向右下方移动,无须遍历整个链表就可定位到目标元素的位置。
时间复杂度分析:查找、插入、删除都是O(logn),假设元素个数为n,每两个结点提取一个结点建立索引,那么每往下一层走相当于节点数目减少一半,走到最底层就逼近答案,粗暴的理解,查询时每次减少一半的元素的时间复杂度都是O(log n),比如二叉树的查找、二分法查找、归并排序、快速排序。
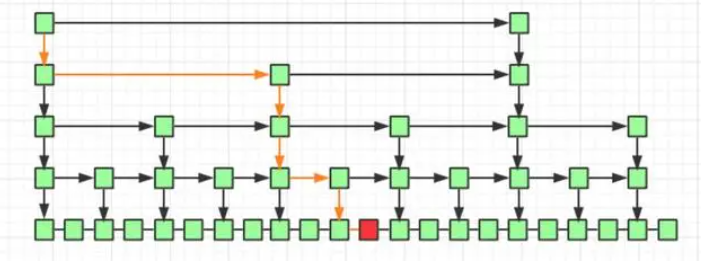
下面是leveldb中跳表源码的大致框架,对外开放的接口主要有Insert和Contain。
- Insert用于向跳表中插入一个Key,本质上是插入一列。
- Contain用于判断某个key是否存在。
为什么没有删除Key呢?不能有!因为删除的时候需要这个标记把之前的标记无效化,如果你在memtable里面加这个删除操作,那刷盘的时候就没这个key了,那之前的版本就能被读到了。
其他Seek,Valid,Next等操作放置于SkipList的内部Iterator中。在对Memtable进行读时,主要是对Memtable的迭代器进行使用,Memtable的迭代器类型取决于Memtable索引数据结构迭代器的类型,在leveldb中,使用的是跳表,这个是可以更换的;进行写时,调用Insert即可。
1 | template <typename Key, class Comparator> |
Insert
下面说说跳表是如何实现Insert的。因为跳表是单向链表,所以对于链表的插入应该找到前驱节点,前面说过Insert操作本质上是插入一列,因此我们需要找到每一层Key的前驱节点。Insert中主要分为三步:
- 找到每一层的前驱节点
- 确定层数
- 自底向上按照链表的方式进行插入
首先是通过FindGreaterOrEqual找到每一层的前驱节点,算法很简单,就是对每一层,找到一个prekey,满足prekey < key < prekey->next的位置。搜索起点从跳表的左上角开始,然后逐渐下沉,直到到最后一层,并不需要每一层都从起点开始,当前层的搜索是基于上一层的搜索结果作为起点的。
确定层数是选择大于原层数的一个随机层数,为什么选择随机,目的还不是很清楚。
最后就是插入,这里插入的方式是从最底层到最高层插入,目的是为了防止并发情况下的错误。如果先将NewNode从高层链入,假设此时有一个并发的search操作到来,当该search操作到达这个node之后,它可能会顺着该node向下移动,但此时NewNode下层的next指针还没有设置完,从而导致错误。(参考康巴尔)
1 | template <typename Key, class Comparator> |
Concurrency
在源码中,maxheight 和 node->next使用了原子变量std::atomic,对它们的读写使用了 std::memory_order_xxx,这些是什么?为什么要用这个?
- 首先说目的,并发编程下,锁常常是性能瓶颈,当我们想绕开锁时,就必须得使用原子指令,但是原子指令假如要实现顺序一致性并没有想象中的快,所以可以做一些一致性的取舍。leveldb在此处通过了原子操作和内存顺序做到了无锁并发,提高了性能。
1 | // Accessors/mutators for links. Wrapped in methods so we can |
以下说明参考了以下博客:
(6 封私信 / 2 条消息) 如何理解 C++11 的六种 memory order? - 知乎 (zhihu.com)
理解 C++ 的 Memory Order | Senlin’s Blog (senlinzhan.github.io)
leveldb中的简单使用如下:
在Insert函数中,有三处中使用的是
std::memory_order_relaxed,std::memory_order_relaxed:只保证当前操作的原子性,也就是说在该条命令之后的命令可能被排到该命令之前,会影响线程间的同步,其他线程可能读到新值,也可能读到旧值。其中两处用在Insert函数中新节点的插入和设置,因为新节点的插入是不存在读到旧值的情况,读不到只是意味着还没插入成功,这个结果是可以接受的,所以可以用宽松一点的要求,还有一处用在Insert函数的最大高度设置,如果读到旧值,也就意味着对SkipList的操作不是从最高层开始进行的,下层的节点更多,并不会影响操作的正确性,因此也可以用宽松一点的要求。剩余的两处用在普通节点的读写(Next和SetNext),用的是
Release-Acquire ordering模型,这种模型限制了自己线程内的指令重排,store()使用memory_order_release,而load()使用memory_order_acquire。这种模型有三种效果。- 在
store()之前的所有读写操作,不允许被移动到这个store()的后面。 - 在
load()之后的所有读写操作,不允许被移动到这个load()的前面。 - 假设 Thread-1
store()的那个值,成功被 Thread-2load()到了,那么 Thread-1 在store()之前对内存的所有写入操作,此时对 Thread-2 来说,都是可见的。
例如下面例子,B永远不会被重排到A之前,C永远不会被重排到D之和,且C一旦load到之后,B之前的A是对C可见的。
这样就保证了leveldb中,某个写之前的操作是对某个读操作是可见的,是合法的,对于一些读写操作,顺序不一致问题可以接受,但是接受不了出现一些中间态,比如说,我明明写了,但是还是读不到。这里虽然没有保证顺序一致性,但是提高了性能。
- 在
1 | std::atomic<bool> ready{ false }; |
Status
用于记录leveldb中状态信息,保存错误码和对应的字符串错误信息。
1 | private: |