Project3——- QUERY EXECUTION
Instroduction
通过前面两个Lab,我们已经完成了Buffer_Pool和Access_Methods的构建,但仍然和上层接口有一定距离,用户在使用数据库时是通过Sql语句进行使用的,在数据库系统拿到一个Sql语句时,究竟需要做哪些工作呢?
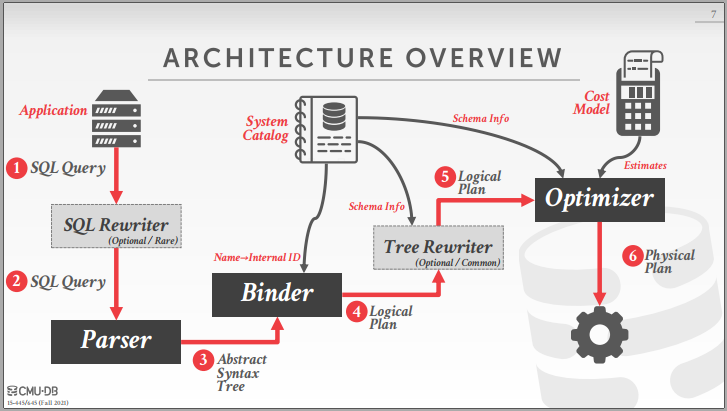
- Parser:简要来说,就是解析Sql语句字符串,获得抽象语法树。
- Binder:简要来说,就是解析语法树,生成逻辑执行树。
- Optimizer:通过成本模型进行查询优化,输出最终物理执行树(由Operator组成)。
在本Lab中,我们需要完成的内容就是”火山模型“下物理执行树的各个Operator的实现。

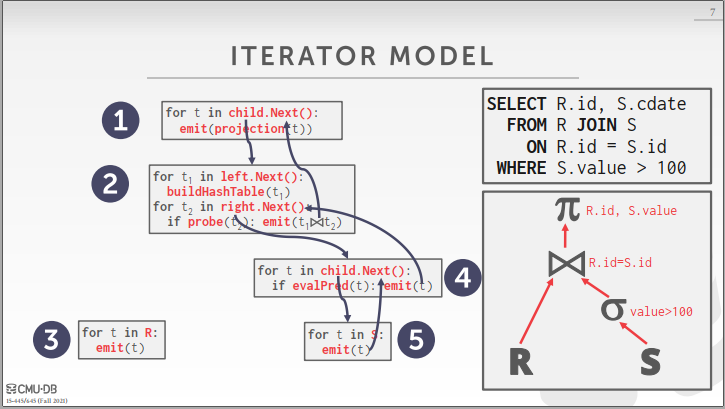
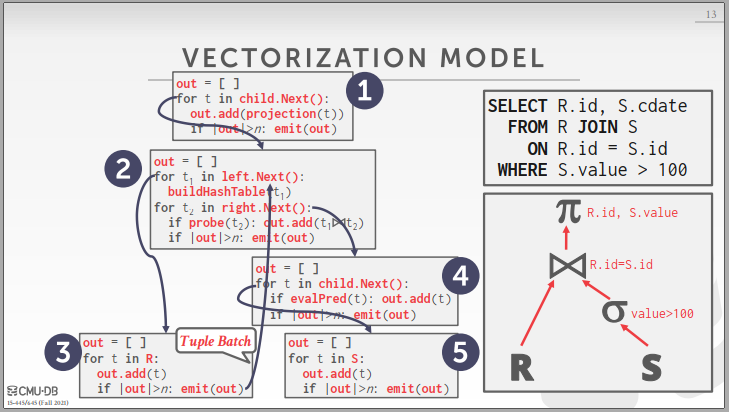
Iterator Model/Vocano Model
在CMU15445中介绍了三种执行树模型,下面主要谈谈各个模型的不同和优缺点::
Materialization Model和Vectorized Model都是建立于Iterator Model之上的,三种model的主要区别在于,每个Operator每次被调用时处理的数据规模不同。
对于Iterator model中的每个Operator,内部需要实现一个Next函数,父Operator通过调用子Opertor的Next函数获取1条数据,然后进行处理,如图所示,整个执行树结构呈现出一个环的形式,这种方式的优点在于,Operator设计具有了一致性,系统扩展性较好,其次对于磁盘型数据库,从磁盘中读一条数据后,Iterator model能够在内存中尽可能地处理完(PipeLine)之后再抛弃数据,相比之下如果一次性读入很多数据进内存并处理很多数据,则BufferPool会频繁地进行换页,这就会造成大量的磁盘IO成本,这是难以接受的。缺点则在于,Iterator model在处理1条数据时,会调用大量的函数,函数上下文切换开销较大。
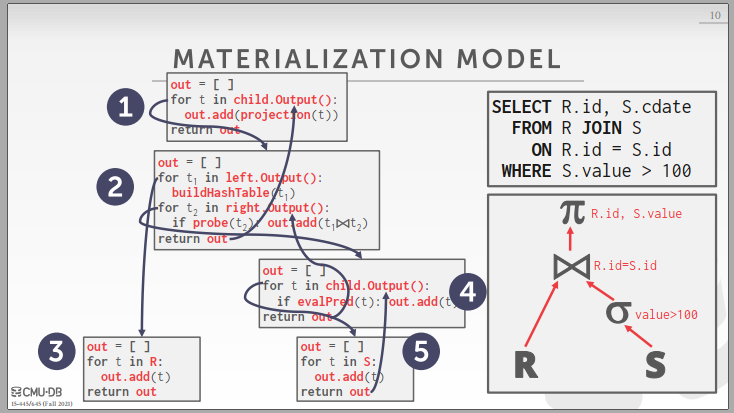
对于Materialization Model,其实也是类似Iterator Model,但它的Next函数是返回全部数据,减小了函数上下文切换开销,但很显然,这种方式在数据规模大的系统下效率并不高,主要应用于数据规模小的内存型数据库系统。
Vectorized / Batch Model ,则是上述两种模型的综合,每次返回部分数据,按批次处理数据,可定制化能力较好,性能也较高。
Coding
整个实验完成过程主要是阅读源码的过程,思路设计上没有很大的难点。代码中,每个Opertor对应一个executor,每个executor中附带了该OP执行的附加信息(自带的plan以及自定义的内部其他数据,plan中有谓词(使用表达式树进行构建),输出格式,所用表信息,Join列信息等),利用这些附加信息完成各个OP的Next函数逻辑即可。
有点细节的是Nested_Loop_Join和Hash_Join需要注意重复元素的连接,一个Input Table中的元素可能对应一个Output Table中的多个元素,因此不能无脑取两个子节点的Next。
对于Nested_Loop_Join,应该判断上一次Input Table的Next的元素对于Output Table是否查找完了,没查找完就应该延用上一次Next的元素进行查找,查找完了再取下一个Next,并对Output Table的executor重新Init。
对于Hash_Join,Input Table加入的哈希表应该是一个Key对应一个vector<Tuple>,然后Output Table进行查找时,需要判断Output Table上一次Next的元素对应的Key在哈希表中的vector是否用完了,用完了才能取下一个Next。
Result