Project2——- Extendible Hash Table
目标:实现一个Extendible Hash Table。
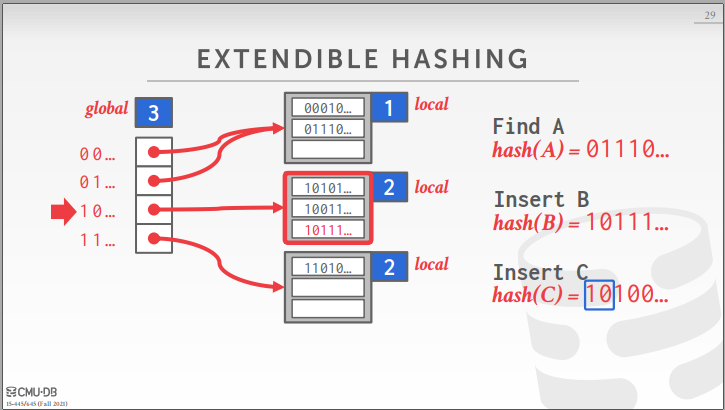
这里简单说明一下为什么要有这种可扩展哈希表?
- 首先,哈希表,分为静态哈希表和动态哈希表。静态哈希表指的是提前分配好空间,这个空间必须比所需空间大(通常是需求量的两倍)。动态哈希表的空间则是进行动态扩展。
- 然后,两者有什么优缺点呢?首先,静态哈希表在所分配空间较大时,插入添加删除等操作代价较低,操作简单,但是它的缺点就是需要提前知道所需的最大空间,且空间占用大。动态哈希的优点就是,无需提前分配空间,减少了空间占用,也无需提前知道空间要多大,缺点就是插入添加删除需要承受其他的代价(例如本次实验的分裂,收缩等)。
- 这里的可扩展哈希,让我想到了拉链法的普通哈希,其实拉链法准确来说应该也算动态哈希的一种,但是它的缺点就是在每个桶数据量较大时,插入查找的时间复杂度就不是
O(1)了。
在理解可扩展哈希时,我参考了下面这个博客的一些讲解。(这种哈希表国内资料也太少了)
(19条消息) Extendible Hashing_计科学习者的博客-CSDN博客
TASK #1 - PAGE LAYOUTS
在这个Task中,主要需要实现存储可扩展哈希表数据的两种页:hash table directory page 和 hash table bucket page。
Design on top of the underlying page
在刚看这个实验的源码时,我非常好奇,为啥看不出这两个类和在上一个实验中实现的page类有何关系,按照hash table directory page 和 hash table bucket page是page的一种的这个思路来说,不应该是这两个类继承于page类吗?
后来研究源码发现,这两种类从数据层面来说,只是page类中的一部分。hash table directory page 和 hash table bucket page这两个类的内容全部装在 data_中,且严格限制这两个类对象的大小为PAGE_SIZE。那这里假如我作为一个更高级的类,想要用底层的类的一些接口,该如何保证呢?注意,这里Page类中的数据成员data_是Page类的第一个数据成员,在C++底层模型中,每个类对象内的成员数据是按照顺序排列的(这里指的是没有虚继承或者虚函数的情况,假如有虚继承和虚函数,数据中间会穿插虚指针,虚指针的位置根据编译器而定,只有在父子类对象强制转换时,获取成员数据才会通过编译器的识别处理指到正确的地方,具体看《深度解析C++对象模型》,这里就不具体展开了),假如要使用,直接通过指针的强制类型转换,这样指针指到的初始位置,又是一个上层类对象的初始位置,也是一个下层类对象的初始位置,根据指针类型的不同,判断指向数据的长度,这样就能根据指针正确调用接口了。
1 | class Page{ |
Data Structure
这里主要谈一下bucket page的设计:由于bucket page中只存哈希键对,因此设计的初衷肯定是一个页中存储尽可能多的数据,occupied和readable组合共同来判断每一处的数据是empty、occupied还是tombstone。为了节省空间,这里用的是按位来存储状态,相较于bool,更节省空间,一个bool一个字节8位。
那occupied和readable数组的大小是怎么定的呢?为什么键对的数组大小为0?
由于页的总大小是恒定的,因此可以通过如下计算:设一个桶装
x对数据,则 x*size(MappingType) + 0.25*x=PAGE_SIZE。x即为所求的BUCKET_ARRAY_SIZE。然后一个char一个字节8位,数组的大小就大概是BUCKET_ARRAY_SIZE/8,这里是用是向上取整,具体就不细究了。尾部在数据类型不同时,可能会多出一些废的空间,这里使用char的原因,就是char比较小,好调整,能尽量多那么一两个char来存状态。这是一个Zero-length array(零长度数组)。它位于结构体/类的最后,本身不占用空间。在声明结构体的时候分配内存,去除掉其他元素的部分就是零长度数组可以访问的部分。
从理论来说,可能只要一个occupied数组也能解决问题,因为**tombstone主要解决的问题是开放寻址法中,第二次搜索出现中断的问题**,由于这是一个允许重复key的哈希表,在GetValue时需要遍历整个bucket的所有数据,不存在中断的问题,因此可以不需要readable数组。
1 | /** |
之后就是具体函数的一些位运算技巧了,具体看代码:
1 | template <typename KeyType, typename ValueType, typename KeyComparator> |
TASK #2 - HASH TABLE IMPLEMENTATION
整体框架:
- ExtendibleHashTable类
- 对外有三个接口:
GetValue、Insert、Remove - 成员包括:
hash table directory page,hashfunc,buffer_poll、table_latch。
- 对外有三个接口:
SPLITTING BUCKETS
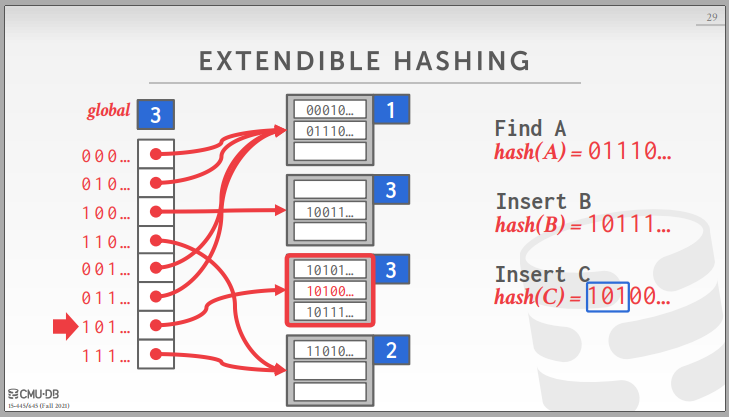
什么时候需要桶分裂?当插入时,该桶满了,则需要增加该桶的深度,并分裂出一个桶。分裂桶最关键的有两点,一是重新分配数据,将一部分数据移至到新桶,这个根据各个数据的key重新计算映射即可;二是更改指向原桶的IDX的指向,有的仍指向旧桶,有的变为指向新桶了,例如在GlobalDepth=5的情况下,LocalDepth=3的00100进行桶分裂,指向原桶的有00100,01100,10100,11100,在分裂后,01100和11100应该指向新桶(一个坑,漏了这一步,只更改了分裂出的两个桶,导致一直查询错误)。
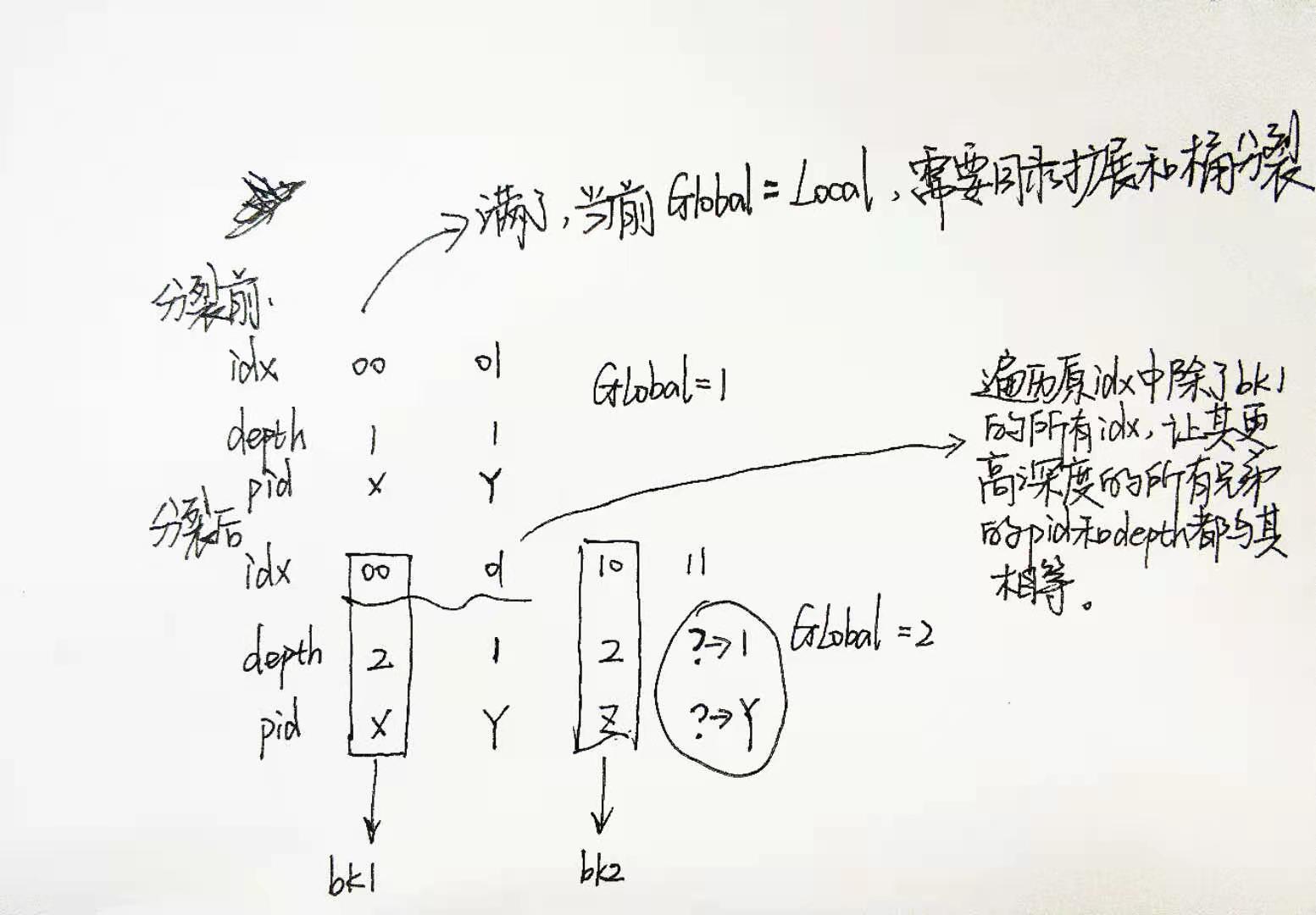
DIRECTORY GROWING
什么时候需要目录扩展?当桶分裂时,分裂前的深度和全局深度相同,则需要扩展目录。扩展目录最关键的就是,重新建立各个IDX与page_id的映射以及各个IDX的局部深度。从下面那个手稿图可以看出,由于扩展了目录,新增添的部分IDX的depth和pid都没有得到定义。重新建立映射关系的思路是:遍历原IDX中除了bk1的所有IDX,让其更高深度的所有兄弟的pid和depth都与其相等(核心原因是更高深度的位没起到作用)。
MERGING BUCKETS
当Remove导致桶为空时,则需要判断是否需要合并桶。实验说明中给了三个条件:
- Only empty buckets can be merged.
- Buckets can only be merged with their split image if their split image has the same local depth.
- Buckets can only be merged if their local depth is greater than 0.
合并桶的关键就是,更新所有指向原桶的IDX的数据(深度,指向),不只是被删桶那一个桶(与Split类似)。由于网上没有Merge过程的图片,我就具体地说一下,比如Local Depth=4的0001为空,那么它需要找1001来合并(因为最高位没用了,剩下的位需要保持一致),如果1001的Local Depth的深度和0001一致,则允许合并。首先删页,然后0001和1001的Depth减一,然后将所有指向原桶的IDX(比如全局深度为6,那么100001,110001,010001,000001都指向原桶)的深度和指向,都改成和1001一样。
一个没考虑到地方:桶合并是个迭代的过程,例如00和10对应一个桶,01和11对应两个桶,当00和10的桶为空时,其另一半的桶深度与其不一致。那当01和11两桶合并之后,也应该将00和10的桶合并起来。推广便知,这是一个循环的过程。我的代码中是,在每次Merge成功后,重新遍历所有桶,如果是空桶则尝试再次合并。
DIRECTORY SHRINKING
在Merge后,如果所有桶的深度都小于全局深度,则允许目录收缩,循环收缩至所有桶深度最大值即可。
TASK #3 - CONCURRENCY CONTROL
这个实验中,主要用到两个层次的锁,一个是表锁,一个是页锁。
表锁在WLock时,其他线程对表或者页的读写操作都不能进行;
表锁在RLock时,表和页只能读,不能写;
页锁在WLock时,其他线程对该页不能读写;
页锁在RLock时,该页只能读,不能写;
总体来说,就是两种不同粒度的锁。这里有个误区需要自我纠正一下,起初我看到table_latch是在ExtendibleHashTable类中的,该类中只有目录页id以及buffer_pool,我以为锁只对该类内的对象起作用,也就是buffer_pool,然后代码也只在buffer_pool上下文进行添加table_latch,发现并不能这么理解,应该是所有相关的数据都得参与进来,具体看如何使用,不只是类内数据,正确理解还是如上所示。
Buffer_pool
所有对页的Fetch和New之后,在使用完记得UnPin,否则永远会占用Buffer_pool中的空间。
Corner Case
在Current_ScaleTest中,出现了GetValue失败。下面描述一下整个Debug的过程:
起初,我在扒下测试代码后,发现它给的buffer_pool容量很小,在我更改到更大时,代码成功率大大提升。因此我怀疑是,Fetch和New没有合理地Unpin,导致Buffer_pool满了。在我确定正确后,移除了这个可能性。
由于GetValue失败,我又以为是Insert和Remove之中可能出现了问题,在检查代码后,我尝试了不同的数据量,在非并发和并发的条件下,测试了两个接口,发现都能正确完成。因此,我觉得这两个接口应该没问题。
在代码中,GetValue中用的table_lacth的读锁,Insert和Remove用的table_lacth的写锁,按理来说,在读的时候,不可能出现中途插入和删除的现象。
因此,我提前插好数据,然后进行并发的读,发现出错了。如果GetValue改成写锁,也就是说只能有一个线程进行读,又一直成功。所以问题就出在这里。
设计上肯定是允许并发读的,后来发现是Unpin的Is_dirty把False设置成True了,导致的问题。起初我写代码的时候,想的是无论是不是脏页我都进行刷进磁盘,这样肯定不会丢失数据啥的,更安全。那为什么这里False改成True就不行呢?考虑如下case:
线程A 线程B Fecth(1) Fecth(1) GetValue后,Unpin(dirty) 页1被替换出buffer_pool,由于是dirty的,则需要重写到磁盘中,位置信息可能发生更改 GetValue(1),此时1指针指向的页可能就不是原来的那个页了
最后Unpin改为false所有问题得到解决。
Result
总结:感觉整个实验难度还是不小,尤其是映射关系添加更改这一块细节太多了,很容易因为一个小故障而导致全局瘫痪。要说收获,感觉最大最实用的收获就是锁,特别是多级锁的使用,需要明确上下级的关系,才能保证不死锁,不出现并发的问题,而且写代码时还是最好从粗粒度的锁开始写,虽然慢一点,但是容易对。其次就是学到了底层页的设计,除了public继承,又学到一种“Is a”的类关系的设计方法,其他的就是编程调试的一些综合能力的提升,整个实验前后花了7天(摸了两天),速度感觉有点缓慢,Debug花太久了!!!最终结果的rank排名排到43,不算太差吧,下个实验见。
