前言
上学期做的Lab123,之后由于开题的事情给耽误了,这次重新拾起来,做起来好吃力 :(
Structure
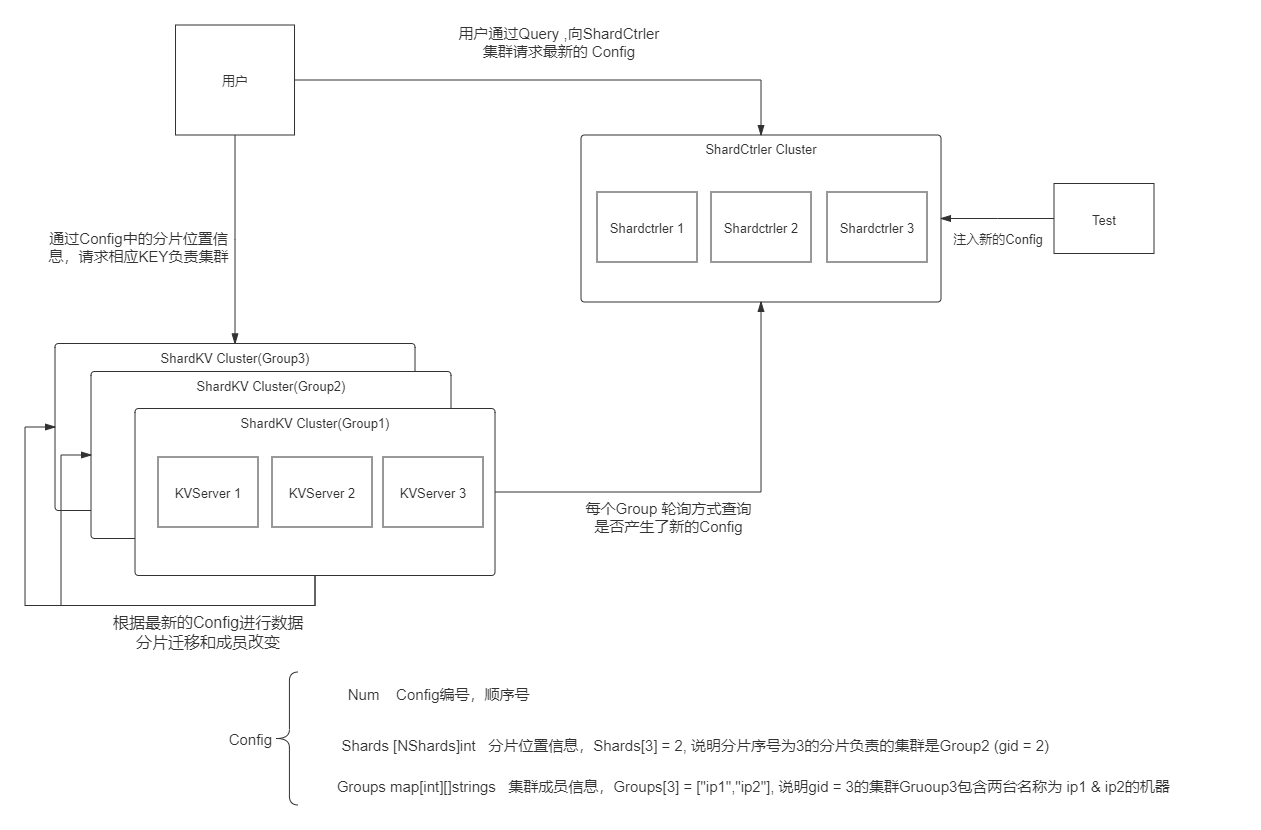
- 具体目标是:创建一个 “分布式的,拥有分片功能的,能够加入退出成员的,能够根据配置同步迁移数据的,Key-Value数据库服务”。
- Client:向ShardCtrler请求获得最新的Config,Config中有”数据存在哪“的信息。
- ShardCtrler:管理Config数组,保存有历史版本的配置信息,并且能够根据shardclient的请求构建新配置。
- ShardServer:有多个Group组成,每个Group保存数据库中的一部分数据,所有Group构成一整个数据库。
- 每个Group和ShardCtrler都是分布式的,有底层Raft节点保证容错和一致。
Lab4A
思路
- 目标是:构建ShardCtrler,支持以下四个操作,并且每个版本必须尽量负载均衡(Shard在各个Group上分散开来)
- Query:查询某个版本或者最新版本。
- Leave:让某些Group离开集群
- Join:让某些Group加入集群
- Move:强制让某个shard分片移动到指定Group中
- 从以上可以看出,Query操作并不更改数据,就对应Lab3中Get操作;其他三个则对应Lab3中的Put/Append操作,参照Lab3复写即可。注意Query同Lab3中的Get一样,同样是交付给Raft后,达成一致后再做出响应,防止在集群失联的情况下返回错误信息。
- Leave和Join时,需要对所有Group重新进行Balance处理。
Balance逻辑
整体来说,想要用最少的移动次数调整成负载均衡的模式,就是多向少进行移动,但是又因为是整数个Shard的原因,那必然会有些Group的Shard会大于平均数,但是最多只会多1个。因此,博主设计了如下思路:
根据Group数量和Shard数量,计算平均数Average,余数left,维护一个尚未分配的shard集合。
遍历Group,进行多的删减。如果left>0,则允许当前Group的shard数量为Average+1,然后left– ;如果left==0,则当前Group的shard数量最多为Average。这个过程中将删减的shard添加到未分配的集合中。
遍历Group,进行少的增添。使用未分配的shard将shard数量少于Average的Group添加成数量为Average即可。
注意Balance算法必须是确定性算法,Go语言Map的遍历是不确定的,容易踩坑。
代码是两重循环,时间复杂度是O(m*n) ,m是Group数量,N是Shard数量,由于这里N较小,因此这个算法勉勉强强,应该有更高效的均衡算法。
1 | //set表示Group的gid集合,排过序,保证确定性。 |
Lab4B
目标
目标是:实现一个ShardKVServer,数据分区存储,能够根据最新配置进行数据迁移,并对客户端做出正确响应。
challenge1:当一个Group失去一个shard的所有权时,副本组需要删除该shard数据。
- 对策:不能在拉取新Config时进行删除,必须保证数据发送成功后,才能删除。
challange2:在Config更改期间继续执行不受影响的Shard中的 key 的客户端操作。
- 对策:数据迁移按照每个shard进行区分,数据库的数据和状态也按照shard进行区分。
第一个坑
刚看代码时,第一反应就是先写获得新Config的代码,在获取到新的Config之后,然后对数据进行迁入和迁出。
踩的第一个坑就是:不断地拉取最新的Config,并没有判断当前数据库的状态。
正确的处理是:
不能直接拉取最新的配置,配置的更改只能+1的递增。为什么?
跳过一些配置,会失去一些中间状态的数据。例如,当前GroupA在config1,GroupB在config6,然后某个shard的数据在config6的状态下是属于A的,在config1的状态下是不属于A的,这时候客户端在config6下向Server提出Put/Append请求,然后会一直失败,因为这个时候的server,GroupA认为数据不是它的,B也认为不是它的。这时候到达了config7,在config7下,该shard是属于B的,若A直接到达了config7,则本应该在6到7过渡的过程,数据从A迁移到B,但是A跳过了6,则B就丢失了这一部分数据。非法!
当数据迁移时,不能拉取新配置。为什么?
这个很好理解,例如当前GroupA在config1,GroupB在config1,然后二者想要更新到config2,这个过程是A向B传数据。假如A发送了数据就认定自己发送完了,就拉取新配置到了2,但是B没接收到数据,之后A在config2时就不会发原来的那些数据给B了,因为它认为自己没有了这些数据。B就会一直没有接收到这些数据。
基于以上考虑,Kv数据库变量设计为:
1 | type ShardKV struct { |
整体思路
踩完这个坑,明确了最关键的两个逻辑,之后的设计就相对简单。
整体思路是:
- 开一个后台协程PullConfig,监控In_state和Out_state。若全部正常,则拉取Num+1的配置。拉取成功后再次,检查In_state和Out_state(RPC回复时,状态可能已经被更改),若正常,则将配置更新指令传递给Raft使当前Group的所有server达成一致。
- 开一个后台协程SendData,监控Out_state。若某个state为true,则发送数据。在收到OK的回复后,再次检查Out_state将更改Out_state的指令传递给Raft。
- 每个Server都有一个接收数据的RPC,在接收到命令时,判断自己是否需要接收。如果ConfigNum小于自己当前的ConfigNum,则回复OK,如果自己的In_state为false,回复OK。以上两个检查是为了正确回复超时的Rpc。如果ConfigNum大于自己当前的ConfigNum,则拒绝回复。如果都不满足以上,就证明自己确实需要接收数据,则包装数据后交付给Raft层。
- 客户端的请求还需要带上ConfigNum,必须要和Server端版本相同。
这里单独说明一下,为什么客户端版本号也要按照分片设计。考虑如下的case:比如一个APPEND 在向A发送后并执行成功,返回时TIMEOUT了。这个时候A server 已经做了这个更新操作。在这个点之后,发生了config更新,由于客户端以为没有成功,客户端就在当前版本的config去问B SERVER发送APPEND。如果只是迁移了SHARD DATA过去,则会造成APPEND 2次。所以我们还需要把去重的MAP也一起发过去,所以版本号也要分片设计。除此之外,数据迁移的参数除了要诉说我是哪个SHARD之外,还需要加上CONFIG NUM,因为有可能我发的CONFIG NUM比那边还要大,说明那边的CONFIG还没同步到。只有具有相同config的Group之间才能进行数据迁移。
说到这里,数据迁移的Rpc参数就设计如下:
1 | type Accept_Args struct { |
判重
下面再说说对脏数据、旧数据以及旧指令如何判重。由于对于数据库的更改只在Raft返回消息后才统一进行修改。因此,最有效的判断时机,就在于此,之前所有的判定只是为了避免将一些无效的log日志交付给Raft层,减少一些不必要的网络通信。以下是Raft层返回的5类消息:
1 | switch msg_op.Optype { |
- Put/Append,判重根据对应shard的Client指令版本号即可,必须大于最新版本,才能做出修改。
- Get,一般不判重,因为返回最新的数据库就符合客户端的需求。但是这里也做了一个特殊处理,如果像Lab3那样,在server收到管道另一端消息后才去读取数据,有可能在这个管道传输消息的过程,数据已经被Delete了,因此这里返回消息之前直接将结果注入到管道消息中。
- 以上两类指令和Lab3还略有不同,考虑如下一种case:在请求发送的时候,数据还在GROUP 1。可是到消息从RAFT返回来的时候,当中发生过更新Config1。数据不在GROUP 1了。所以要Put/Append/Get还需要把判断WRONG GROUP的逻辑,加在数据返回层。
- MakeConfig,判重根据ConfigNum大于1的关系,同时再次检查In_state和Out_state。
- Accept_data,判重根据ConfigNum相等的关系,同时再次检查In_state。
- Change_out,判重根据ConfigNum相等的关系,同时再次检查Out_state。
什么对判重如此严格?为什么要明确判重依据?
起初并没有想到数据迁移还有Pull模式这种(就是缺数据的一方主动要索要数据),看了别人的博客才知道,之后对判重这个方面的思考来自如下的一种case:
关于分片迁移的push模式,是否会发生呢?如何解决?groupA和groupB在ConfigNum为1时,B需要发送shard数据给A,并且A接收成功,B发送成功了,然后A和B正常运行到达了更高的ConfigNum,之后若A在没有persist数据时宕机重启了,ConfigNum重置为0了,当它再次到达ConfigNum为1时,是否会一直阻塞在此呢,因为B已经不会再给它发送数据了。
想到这个case以后,我以为Push模式永远无法实现了,因为它会阻塞在这种情况。之后请教了Github上的一个博主,得到了如下回复:
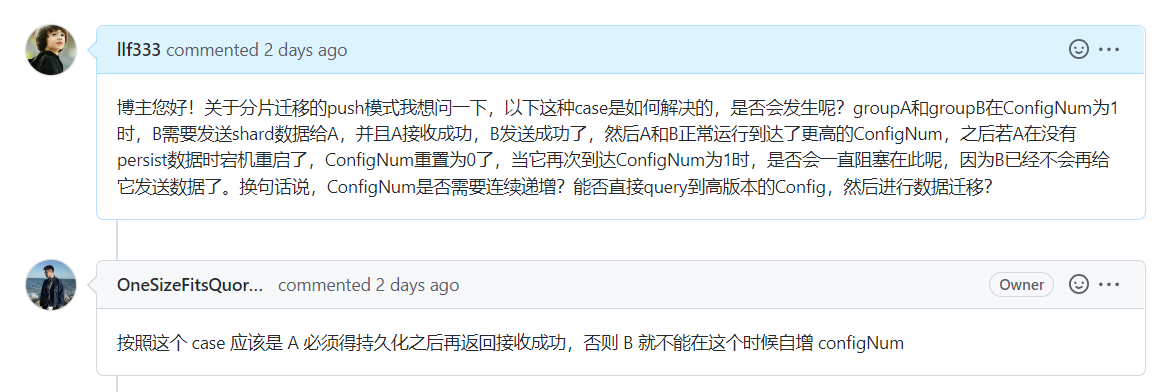
得到这个回复后,我觉得他说的很有道理,我就在想什么是持久化。持久化是SnapShot吗?并不是。Snapshot只是存一个状态,而在这整体的一个架构上,持久化应该是Raft层每次对log进行修改的后persist(),是由Raft层保证可靠性的。对于上面的一种case,当一整个集群宕机后,再次重启时,会根据Raft的日志进行一条条重放,然后恢复到原来的状态。那这里跟判重又有什么关系呢?因为在日志回放的过程中,整个server是处于一个历史状态,这个时候如果来了旧的或者是timeout的数据或者命令,如果旧的状态认定这些旧的命令是合法的,也就是说没有对这些数据和命令做出严格的筛选,那么,在回放时就会出现问题,这些就非法的命令就会插入到原来的log末尾并被执行,那么就无法恢复到原来的状态了。因此,需要对每一类的指令严格判重!所以以上的这种case自然地会被Raft层合理解决,并不用考虑。
一个让人羞愧的坑
SnapShot在压缩数据和恢复数据时,顺序一定要保证一致!以后遇到类似情况一定要小心,卡了我两天 :(
结果
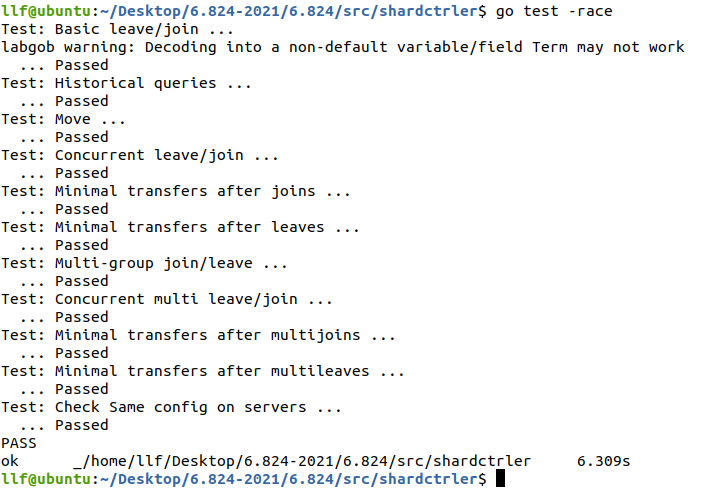
Lab4A:
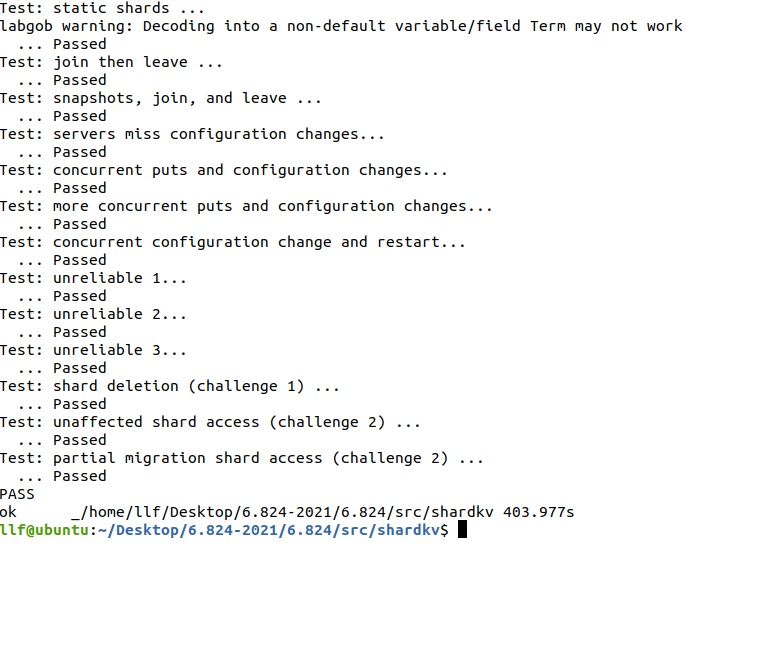
Lab4B:
体会
直到今天6.824Lab也算是做完了,Lecture中好多的论文也还没去细看,感觉分布式是一门超深的学问,水太深了。做完整个6.824,给我的最大感受就是,分布式下的编程,各种操作一定要考虑好操作在此刻的合法性 ,很多Case都来自于,数据返回后状态发生了更改。其本质原因应该是,在并发的环境下,由于消息通信需要时间甚至不可靠,很多条件是否成立需要在当前的环境下重新得到考量,这就对编程增添了极大的难度。当然Debug也是需要技巧,log不能打太多,也不能太少,最好是做到精准有效。
因为博客开得比较晚,这次也只写了Lab4的一些体会,之后有空闲时间再重新回顾一些前面的几次Lab和以前看过的一些书吧,下篇博客见!