MapReduce解决了一个什么问题?
过去,处理大量数据的计算时,通常依赖于一台“超级电脑”,但机器计算能力仍然是有限的,这种方式无法解决无限大规模的数据。
MapReduce作为一种分布式并行计算的框架,它主要从分治的角度出发,能够高容错地组织许多一般性能的机器,将大规模问题进行拆解,在并行计算后再做整合,解决了大规模运算的问题。
现实生活中通常应用于一些分治问题:
- 词频统计
- 网页抓取
- 日志处理
- 查询请求汇总
MapReduce的框架
用户负责的模块
文件分割。
Map:接受一组参数(分割后的文件),产生一组中间键/值对。
Reduce:接收一个中间键和该键的一组值,产生一个可能更小的值集。
具体6.824中,在src/mrapps/wc.go中:
Map接受文件内容,返回一个key/value集合(key是单词,value是1);
Reduce接收一个key和一组value(这个value是1),返回一个总和的value(value的数量就是1的数量就是单词的个数)。
在定义好Map和Reduce的功能后,worker在执行过程时就直接调用这两个接口,进行分布式计算,用户则无需关注内部实现。
程序流程
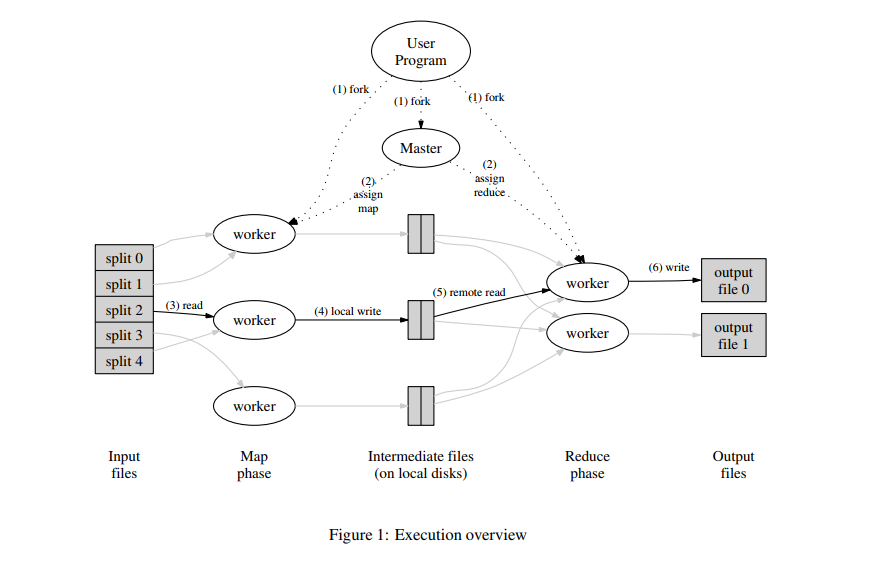
程序主要有两个节点:master和worker。
1、用户定义:文件分割、Map、Reduce
2、master分配任务给worker执行Map任务和Reduce任务
3、Map读文件并计算
4、Map将所有中间结果写入本地磁盘
5、等待所有的Map任务结束后,worker开始执行Reduce任务,远程获取对应worker本地磁盘的中间文件,排序后计算
6、写入最终结果
7、通知用户任务完成
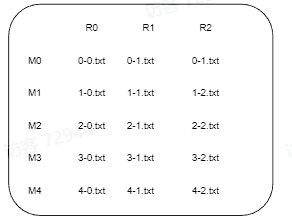
中间文件的命名方式为: M_index - R_index
下图说明了Map,中间文件,Reduce三者的关系:同一行的文件是同一个Map节点产生的,同一列的文件归由同一个Reduce节点负责。
对于一个key_value,其输出到中间文件的R_index为:R_index = hash(key) % nReduce,主要优势有:
将所有的key_value根据key大致均分,保证子任务的大小均衡。
同一个key的结果保证在同一列,由一个reduce统一处理得到总结果。
需要注意的是,中间文件需要写入磁盘,即使这个过程速度相对缓慢。至于为什么,我认为原因主要是worker主要是和master进行交互的,worker之间并没有联系。如果不写入,则需要直接将中间输出结果传输给另一个worker,这个过程涉及到了worker之间的通信,不仅增加了系统的复杂程度,同时网络传输的不确定性可能会导致中间输出结果一直无法得到保存,耽误整个任务的执行。
master数据结构
- 每个map task和reduce task的任务状态(空闲,进行或已完成)
- worker的状态(进行或者空闲)
- 中间文件的位置信息和大小信息
Fault Tolerance
worker
master通过心跳机制检查worker是否在规定时间内完成任务,心跳超时(worker宕机或者是backup task),则标记该worker节点的任务失败,并重置任务状态并分配给其他空闲worker。
执行Map的worker磁盘损坏,则会重置任务状态。为什么Reduce的不用,因为Reduce的输出会记录在全局的文件系统中。
Master
两种方式:
通知客户端重新执行M-R任务。
维护一个检查点,宕机后从检查点后恢复。
Semantics in the Presence of Failures
无论是Map还是Reduce,worker输出都会先将结果暂时写在一个私有的临时文件中,等到任务完成后,再重命名该临时文件。目的是防止多个任务写在同一个文件中,导致内容语义冲突。依靠 文件系统提供的原子重命名操作 来确保最终文件的系统状态仅包含执行一次任务所产生的数据。(这一点6.824Lab并未体现,论文里有说明)
Locality
网络带宽通常是分布式环境下稀缺的资源,由于M-R的文件是放在GFS文件系统中的,Map任务文件的读取通常发生在本地或者是就近的节点上,减少了带宽占用。
Backup Tasks
部分worker执行得很慢,master会分配其余空闲worker进行重复任务,只要其中之一完成任务,就算完成任务。
Refinements
- 自定义hash。可以按照数据想要的分类方法,自定义hash函数,得到相应的Reduce结果。例如,通常词频统计是按照单词的种类划分,其实也可以将同一个主机下文件中的单词划分到一起(hash函数对同一个主机下的单词有着相同的哈希值)。
- 中间结果有序。减轻Reduce任务负担。
- 预处理。在输出中间文件前,进行一次Reduce。比如某个单词word出现了1000次,<word,1>不进行预处理则在中间文件有1000行,预处理后则合并成<word,1000>,中间文件只有一行,不仅节省了网络带宽,也减轻了Reduce任务负担。
- 略过坏记录。数据集并不能保证完全是正确的,如果有一行记录是错误的导致map任务崩溃,不断的重试最终使得整个程序不能结束。因此必然需要跳过这一段错误的记录,如何跳过呢?每个map任务要捕获异常,通过安装信号的方式,在程序退出之前执行安装的信号函数把执行到的文件的行号offset等信息发送给主节点。 主节点在下次调度的时候 将这些offset处的记录作为黑名单列表传递给新的map任务,执行时会对此处的记录跳过执行。
- MapReduce可以本地多进程执行,方便调试。
- 心跳中附加状态信息。方便用户查看整个任务的执行进度。