CAP
C:Consistency
A:Availability(Fault Tolerance)
P:Partition-tolerance
最多同时实现两个。
Structure
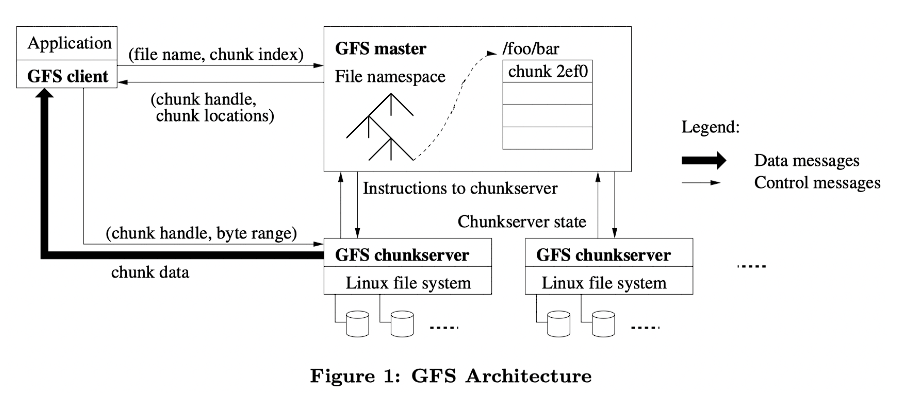
三类节点
client:客户端
master:单中心节点
chunkserver:存储文件数据的节点。
两类数据
master中的元数据
chunkserver中的文件数据
master存储的元数据
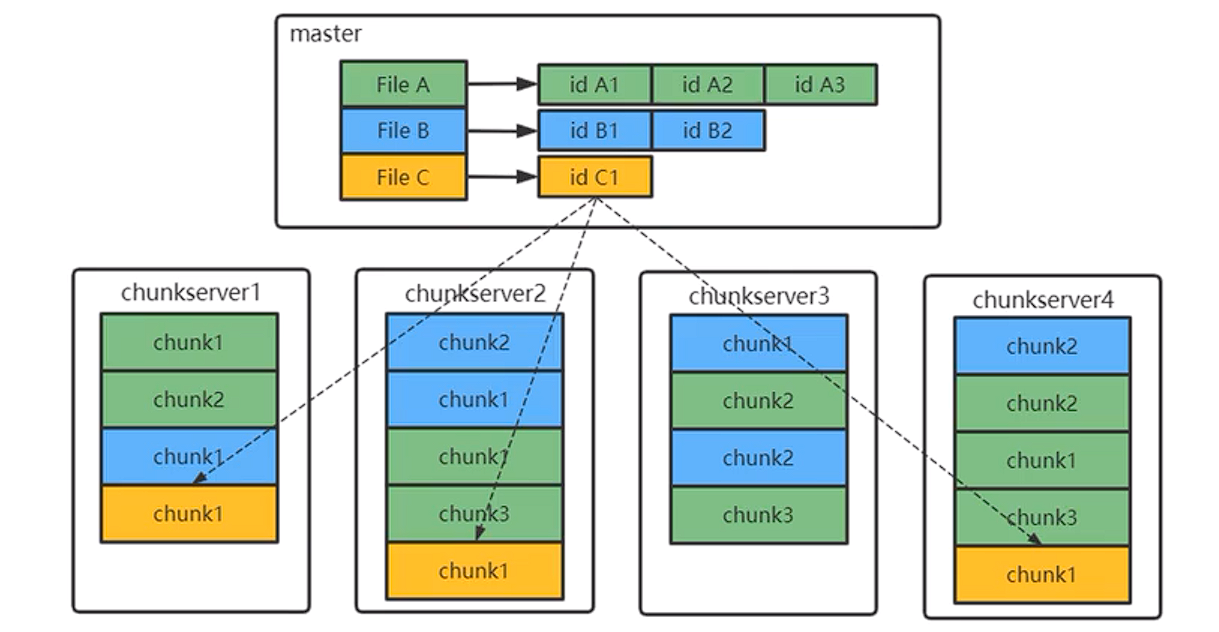
文件namespace(持久化)
文件和chunkID的映射(持久化)
chunkID和chunk位置的映射(不持久化)
为什么第三类数据不持久化,因为这个数据可以在master重启后从chunkserver中获取。
chunk大小为64MB
为什么取这么大?
GFS是对大文件进行设计的,一般是G级别的文件,一般不会有碎片空间浪费。
使chunk数量减少,减少了存储chunk的信息(存储在master节点),节省了宝贵的内存资源。
更容易对一个chunk进行操作,例如要追加40MB的内容,这个操作可能就在一个chunk上完成了(更有局部性原理的特性),但假如chunk只有4MB,那么追加操作可能会有十余次操作,从网络上说,增加了TCP传输负担,从系统上说,增加了系统的寻址和交互次数,影响了系统的性能。
为什么选择单中心节点?
- 更简单可控,单节点的瓶颈并非想象中的严重,有一系列措施进行优化(内存调度,控制流和数据流分离,元数据压缩,增大chunk大小等),多中心节点实现的难度也并非想象中的简单。但这个也是GFS最大的瓶颈。
Availability
master
通过WAL日志对master元数据的写操作进行日志记录(日志记录也有checkpoint(snapshot)功能),这一步可以使得master宕机后能够自动恢复。
主备切换,使用chubby服务:设置有primary master和shadow master,每个写操作都会发送给shadow master,只有shadow master正确记录日志后,primary master才能算操作成功,这一步可以使得master长期宕机后保证有新的master接任。
chunk
首先,这里的高可用和容错概念是chunk层(数据层面)的,更底层,而不是chunkserver层(物理节点层面)的,这样可以保证数据在chunkserver中自由流动,使系统具备超强的可扩展性;相比之下,master的高可用是在物理节点层面上的。
具体思路:
- 对一个chunk的每次写入,必须确保三个副本的写入都完成(并不是大多数,保证读的高效(就近),才能视为写入成功。
- 某个chunkserver在宕机后,导致副本数量不足,则一段时间后master在另一个chunkserver中重建副本。
- 每个chunk有校验和,读取时若校验和不匹配,则chunkserver会反应给master,让master做重建副本工作
- 负载均衡,某个chunkserver负载过高,则会搬动chunk到另外的chunkserver上。
总体来说,有相当一部分的工作移交给master,在master的高可用下,chunk的高可用也得到的保证。
Consistency
Read
是客户端(或者应用程序)将文件名和偏移量发送给Master。
Master节点将Chunk id 和对应的chunkserver发送给客户端。客户端会选择一个网络上最近的服务器进行读取(Google的数据中心中,IP地址是连续的,所以可以从IP地址的差异判断网络位置的远近),读取时需要检查校验和。
Write
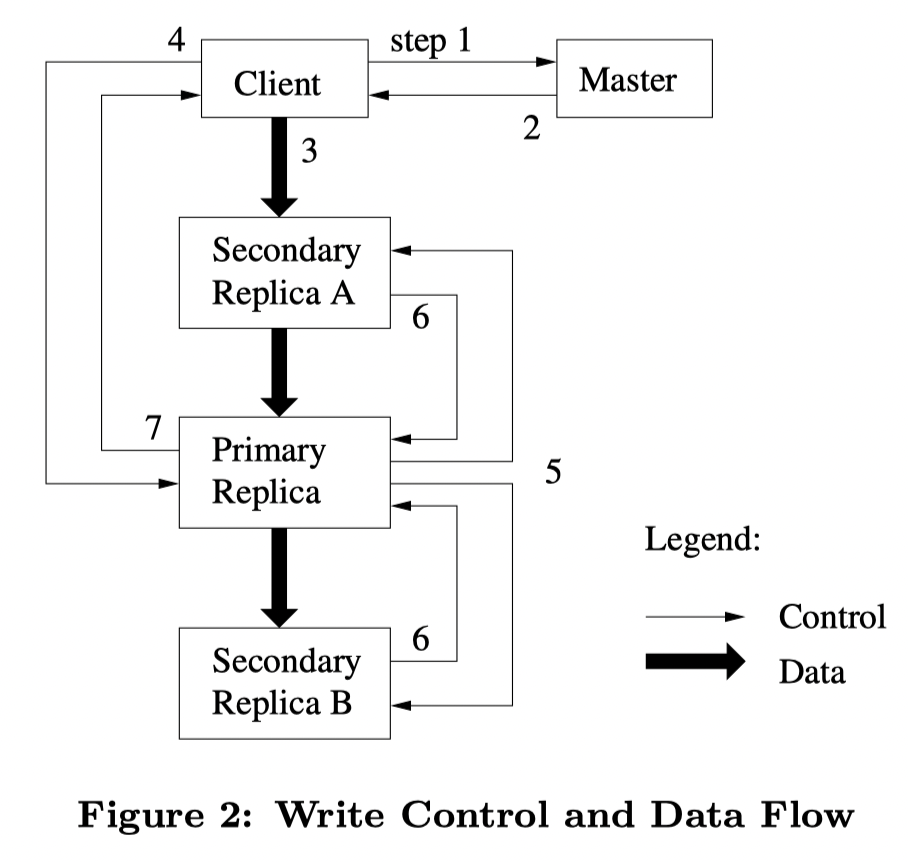
- 客户端询问Master哪个块服务器持有这个块的当前租约,以及这个块的其它副本位置。如果没有一个租约,则Master选择一个副本并授予一个租约(没有在图上显示),并增加版本号。
- Master回复客户端primary的标识,以及其它副本的位置。客户端缓存这些数据用于以后的修改操作。只有当primary不可达或者接收到primary不再持有租约时才需要再一次请求主节点。
- 客户端将数据推送到所有的副本。一个客户端能够以任意顺序进行推送,每个块服务器将数据保存在内部的LRU缓存中,直到数据被使用或者过期被替换掉。通过对数据流和控制流的分离,我们能够通过基于网络拓扑来调度数据流,不管哪个块服务器为primary(如图),以此提高性能,这个在有的博客里面介绍为“流水线技术”,和传统的主备同步(Raft)不一样,直观理解理解就是数据量大的数据流大家有力出力,而数据量小的控制流由primary单独决定。
- 一旦所有的副本都确认接收到了数据,客户端将向primary 发送一个写请求。这个请求确定了之前的数据被推送到了所有副本。Primary为接收到的所有修改操作分配连续的序列号,序列号提供了严格的序列化,这里保证了在这单个chunk的强一致性,应用按序列号顺序执行修改操作,进而改变自己的状态。
- Primary将写请求发送到所有的secondary副本上。每个secondary副本按照primary分配的相同的序列号顺序执行这些修改操作。
- Secondary副本回复primary。表示它们已经完成了所有的操作。
- Primary回复客户端。任意副本上的任意错误都将报告给客户端。在一些错误情况下,写操作可能在primary和一些secondary副本上执行成功。(如果失败发生在primary,它将不会分片一个序列号,并且不会被传递。)客户端的请求被视为已经失败,这个修改的区域停留在不一致的状态上。我们的客户端代码通过重试失败的修改操作来处理这种错误。在从头开始重复执行之前,它将在3-7步骤上做几次尝试。
Record Append和Write
GFS推荐Record Append,而不是Write,为什么?
Write操作可能涉及到多个chunk操作,可能是一个分布式操作,在GFS中,并发Write只能保证副本间的一致,而不能保证这种一致是正确的,为什么呢?例如三个并发write操作123涉及到两个chunk,分别是A,B,在chunkA的primary中定义的写序列可能是123,而在chunkB的primary中的定义写序列可能是321,导致最终结果是A3,B1,但正确结果是A3,B3,这就无法保证结果的正确。想要保证强一致性,则可以使用两阶段提交,但是巨大文件的两阶段提交,一旦有一个chunk文件写入失败,则全局就要等待,代价太大了。
Record Append只会涉及到文件的最后一个chunk或者新增chunk,这里做了两个优化,一是限制Append操作的大小小于64MB,二是在空间不足时直接新增chunk,这种优化保证了atomic,最差的结果是副本不一致,部分副本出现重复Append,但结果仍然是正确的。如何解决重复追加,可以记录文件长度,可以检验校验和等。
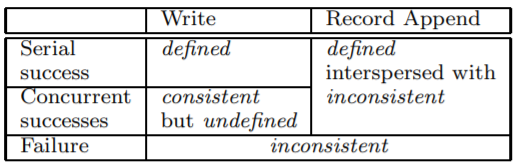
defined:一致且正确
consistent:一致
Split Brain
使用租约机制解决脑裂问题。
在某个时间点,Master指定了一个Primary,之后Master会一直通过定期的ping来检查它是否还存活。因为如果它挂了,Master需要选择一个新的Primary。Master发送了一些ping给Primary,并且Primary没有回应,你可能会认为Master会在那个时间立刻指定一个新的Primary。但事实是,这是一个错误的想法。为什么是一个错误的想法呢?因为可能是网络的原因导致ping没有成功,所以有可能Primary还活着,但是网络的原因导致ping失败了。但同时,Primary还可以与客户端交互,如果Master为Chunk指定了一个新的Primary,那么就会同时有两个Primary处理写请求,这两个Primary不知道彼此的存在,会分别处理不同的写请求,最终会导致有两个不同的数据拷贝。这被称为脑裂(split-brain)。
Master采取的方式是,当指定一个Primary时,为它分配一个租约,Primary只在租约内有效。Master和Primary都会知道并记住租约有多长,当租约过期了,Primary会停止响应客户端请求,它会忽略或者拒绝客户端请求。因此,如果Master不能与Primary通信,并且想要指定一个新的Primary时,Master会等到前一个Primary的租约到期。这意味着,Master什么也不会做,只是等待租约到期。租约到期之后,可以确保旧的Primary停止了它的角色,这时Master可以安全的指定一个新的Primary而不用担心出现这种可怕的脑裂的情况。